Sia across the estate: one agent for all of IT operations

Most "AI for IT" demos pick one trick and polish it. A clever firewall change, or a single compliance report. That is fine for a demo and useless for a real IT org, because no real IT org is one domain. The cloud team, the platform team, the network and security team, the storage and backup team, the database team, and the helpdesk all run different systems and all carry the same kind of toil.
Sia is built for that whole picture. It is the command-line surface for SIA, Scogo's IT-operations agent, and SIA reaches across the estate through Agent Fabric, the layer that connects to the systems you already run. Cloud across the major providers, storage and backup, virtualization, networking and firewalls, security from identity to email and network protection, databases, service desk and RMM, and observability. Scogo connects to more than 200 systems across those categories today.
This post makes that concrete. Here are jobs from five different corners of the estate, each one showing the same agent and the same governance doing real work. The point is the spread, not any single scenario. After that, where we are taking it, and how enterprise teams get their hands on it.
A note up front. The walk-throughs below show how Sia approaches each job using capabilities that exist today: the mutation gate, the approval flow, the audit log, the subagents, the skills, and the integration layer. They are representative operator flows, not transcripts from a specific customer. Any number is marked as a placeholder for us to fill with real data, because I will not ship a figure we made up.

Cloud and identity: an access change on a cloud account
An access request comes in. A role on a production cloud account needs adjusting, and nobody wants to free-hand an IAM change.
The operator describes it in plain language. Sia does not touch anything first. It reads the current policy, works out what the change would actually grant, and checks what depends on the role. Then it proposes the change as a clear before-and-after. The write to the cloud account is a mutating operation through the integration layer, so the mutation gate returns approval-required. It does not run. The operator sees exactly what would change, including any widening of permissions, and approves or denies it in the terminal. After applying, the agent reads the live policy back and compares it to what was intended. If they do not match, it says so rather than claiming success. Every step lands in the signed audit log, which is exactly what you want the next time someone asks who widened that role and when.
[METRIC TO CONFIRM: e.g. access-change turnaround in a design-partner environment, or cut.]
Operating systems: a patch and a reboot across a fleet
Patch Tuesday, or a CVE that cannot wait. A set of Linux and Windows hosts needs patching, and the risk is not the patch, it is rebooting something load-bearing at the wrong time.
The operator asks Sia to handle the round. It dispatches a read-only pre-check subagent first, an agent built without the ability to change anything, to gather current patch levels, find what each host runs, and surface dependencies and anything that looks fragile. The subagent comes back with a structured report and a proceed, pause, or block call per host. Then the agent proposes the plan. Reversible steps, like staging packages or draining a node, flow freely. The reboots, which change shared state, pause for approval, one clear decision at a time through the single-flight queue. The operator approves the safe ones and holds the host that also runs the thing nobody wants to bounce mid-day. The whole round is recorded.
[METRIC TO CONFIRM: hosts patched per round, or time saved, or cut.]
Storage and backup: a capacity alert, handled without making it worse
A storage capacity alert fires. The instinct under pressure, just clear some space, is exactly the instinct that turns a warning into an outage when the wrong path gets force-deleted.
The operator hands the alert to Sia. The agent does what a careful senior engineer would. It investigates before acting. Through the storage system and read-only inspection, it pulls utilization, finds what is actually consuming the capacity, separates reclaimable data from load-bearing data, and checks the usual suspects: runaway logs, an orphaned snapshot chain, a stuck retention job, a backup that never aged out.
Two of the controls matter here in a very physical way. The agent's bias toward reversible action means it builds a full picture before it proposes a single deletion. And if any proposed reclamation involves a destructive command, the mutation gate stands in front of it. The hard block on recursive force-deletes of protected paths means that even a confused chain of reasoning cannot turn "free up space" into "delete the wrong tree." Anything that mutates shared storage pauses for approval, with a preview of precisely what would go. The operator ends the incident with a clear cause, a reclamation they explicitly approved, and a recorded trail, instead of a frantic deletion they are not sure was safe.
[METRIC TO CONFIRM: storage scenario outcome, or cut.]
Databases: a slow query and a risky index
A service is slow and the database is the suspect. This is a job that mixes safe investigation with one genuinely risky action.
Sia reads the slow-query data, looks at the plan, and checks the table sizes and existing indexes through the database connection. All read-only, so it moves at full speed. It forms a ranked hypothesis and proposes a fix, which might be a new index. Creating an index on a large production table is not free, and it changes shared state, so the gate pauses it for approval. The operator sees the proposed statement and the cost note, and decides whether to run it now, schedule it, or do it on a replica first. If the operator approves, the agent runs it and then re-checks the query to confirm the fix actually helped, rather than declaring victory because the command returned. Recorded, start to finish.
[METRIC TO CONFIRM: query investigation example, or cut.]
Security and observability: triage across systems during an incident
An alert pages. This is the case where reaching the whole estate is the entire value, because a real incident never lives in one system.
The operator points Sia at the alert. The agent anchors on the alert payload, pulls the affected service's logs scoped to the incident window from the observability platform, correlates traces if they are connected, and checks for recent deploys or config changes inside the window. It can also check related security signals and recent access changes, because those systems are connected too. It comes back with a ranked root-cause hypothesis, the one piece of evidence that would refute it, and the next two or three checks to run. It does not start a fix. It does not page anyone. It does not file a ticket on its own. Triage ends at a clear hypothesis and the next checks, with every system it touched, across observability, security, and infrastructure, recorded in one trail.
[METRIC TO CONFIRM: triage example, time-to-hypothesis, or cut.]
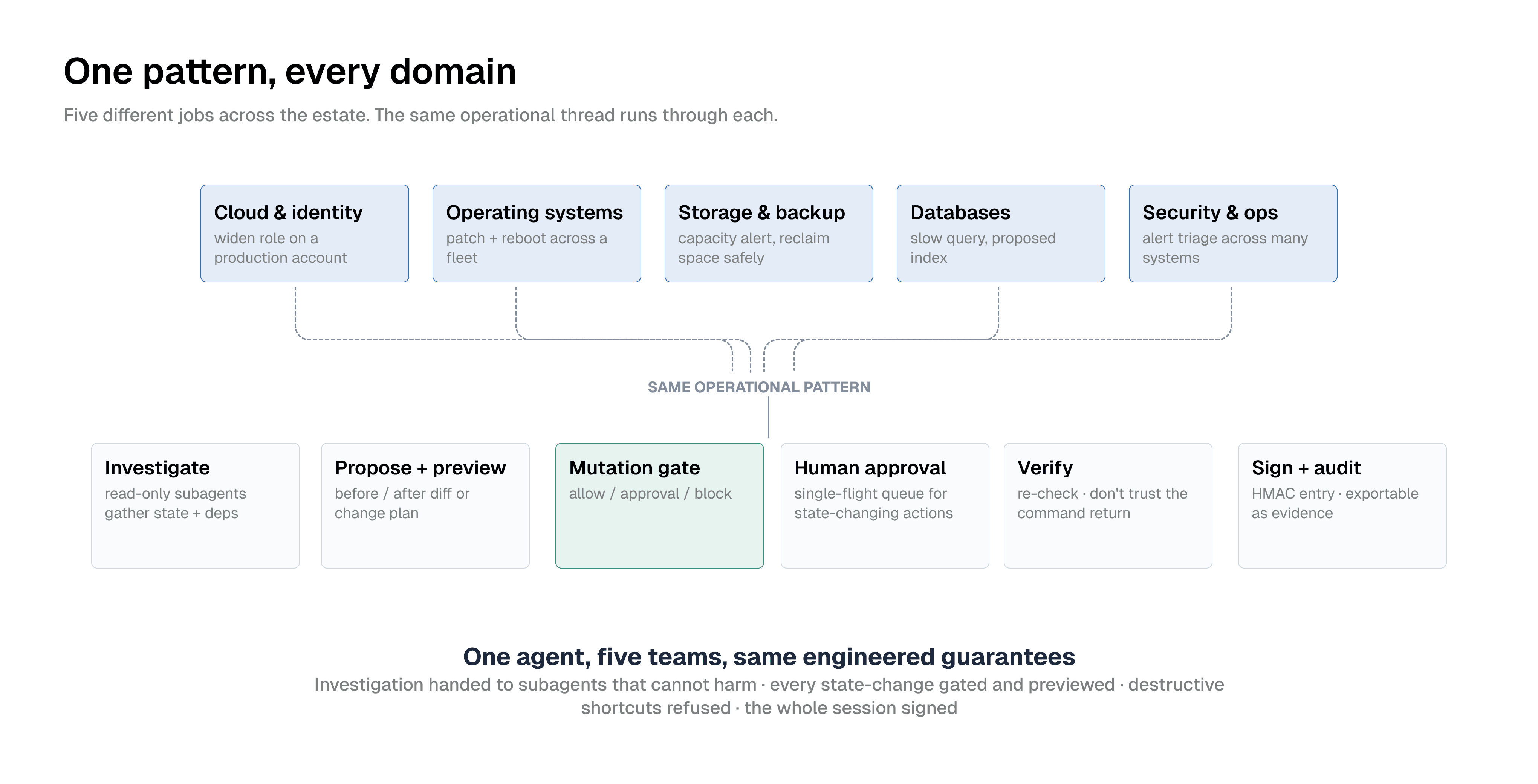
The thread through all five
Look at what these have in common. They are five different teams and five different system types. In each one, the agent does the dense, multi-step, judgment-heavy work, and the governance is not a separate ceremony bolted on top. It is woven through. Investigation handed to subagents that cannot do harm. Reversible work moving at full speed. Every state-changing action gated and previewed. The destructive foot-guns refused. And the whole session landing, signed, in a trail you can export and verify.
That is the payoff. One agent, reachable from one terminal, useful across the estate precisely because it is governed. Useful enough to act, safe enough to deploy, in the cloud team's world and the storage team's world and the database team's world alike.
Where we are taking it
This is a launch, not a finish line. A few directions we are investing in.
Deeper estate coverage through Agent Fabric. More of the systems IT teams run, across more of the categories, reachable from the same surface.
A growing curated skill library. Skills are how your operational know-how becomes something the agent runs the same way every time. We are building out the curated, integrity-verified skill source so more of the procedures your teams run by hand, vendor-specific change workflows, triage playbooks, compliance walks, patch rounds, become first-class, version-pinned, auditable skills the agent can search and load on demand, always from a vetted source.
And continued work on the governance substrate. The gate, the approval model, and the audit trail are the parts we will keep hardening, because they are the parts that make everything else deployable.
I am being deliberate about what exists today and careful not to over-promise unshipped internals or dates. What ships now is the agent, the governance model, the subagents, the bundled skills, and the native integration layer. The curated-skill distribution is being finalized now, and I have described its model rather than its mechanics.
Where this is going
We built Sia CLI for the people who keep production running and the leaders accountable for it. The mission is the same one I opened with. An IT-operations agent that reaches the whole estate, in the terminal your team already uses, autonomous where it is safe, governed where it matters, on the record everywhere.
Sia CLI is part of the Scogo platform we deliver to our enterprise customers. If you are running a large IT estate and the gap between "the systems are programmable" and "the work has not changed" is one you feel every week, that is the conversation I want to have.
Sia CLI is the command-line interface for the Scogo AI platform, the terminal surface for SIA. Available to Scogo enterprise customers.

Written by
Karan Singh
Co-founder & CTO
Published on


